天能 TENET 是一部2020年上映的燒腦科幻動作片,其中出現大量的時空倒轉場景,與其他時空穿越的電影不同,這部片中想要回到過去就得經歷倒轉的過程,因此產生了交錯複雜的時空關係。簡單來說,在這個當下,可能同時出現時間正流的自己、倒流的自己、倒流再正流的自己,這就是導致此片特別燒腦的主因,當然導演也不忘交代時空倒轉的原理,那就是"熵"減。不過這個熵可搞得不少人滿頭問號,究竟它到底為何物,以下就讓我們來看清它的真面目。
什麼是熵?
熵這個字是來自於英文的 entropy,中文讀音為商。可能很多人難以理解熵是什麼,有人說它是宇宙發展的方向,也有人說它是無序的程度,其實只要把它想成是"亂度"就行了,也就是混亂的程度。例如,你剛整理好的房間,是很整齊的,此時就可以說這個房間的熵很小,然而隨著時間的流逝,你的房間就會越來越亂,熵越來越大,我們就稱這個過程為熵增。
為什麼熵減就會時間倒流?
19世紀時,克勞修斯等科學家發現自然界中有一些現象:
- 熱不會自發地、不用任何代價地從低溫物體轉移到高溫物體上。
- 無法從單一熱源取出能量,將它轉變為功而不產生任何影響。
這些經驗法則隨著統計力學的發展,成為了熱力學第二定律:
一個沒有外力介入的環境,其熵只增不減。
上述的無外力介入環境,在物理學中,我們就稱之為“封閉系統”,例如,你的房間如果沒人整理,它就只會越來越亂,此時就是封閉系統的熵增現象,一旦你整理了,你就成為了“外力”,且你為了整理所付出的代價(增加的熵)會大於房間減少的熵。
再舉個例子,行動電源雖然能幫你的手機充電,但其實它沒有辦法百分之百的將所有電量都轉到手機上,會有部分能量以熱的方式散發掉,這就是為什麼充電時,手機或行動電源會發燙的原因,且行動電源用久了,最終也會失去儲電能力,這些都是熵增的現象,簡單來說就是“回不去了”。
從上面的例子,我們可以發現,世界總是往熵大的方向發展,就好像時間只前不退一樣,這就是導演認為只要熵減少了,時間也就倒退了的原因。
其他領域的熵
從上文中,我們可以知道熵指的就是:混亂程度、多樣性、能量退化指標。在不同領域也引進了熵這個概念,像是生物學、生態學的熵就是生物多樣性,而資訊學中的熵,則是資訊的平均量,或說是資訊的不確定性量度,我們稱為資訊熵,或是夏農熵(Shannon entropy)。
深入理解資訊熵
!!注意!以下沒有暴雷,但有數學公式!!請慎入,若無興趣者可以跳過此段!!
一般人解釋資訊熵的方式還是有點抽象,其實只要把它想成是:
得到這個資訊的平均代價。
這樣一來就好理解多了。我們可以透過以下問題進行發想:
假設你是某某學校A班的學生, 而你想知道B班此次的班排第一名是誰, 你有一個朋友在B班, 但他只告訴你前4名的名單(小明、小楨、小華、小琪), 剩下的要你自己去猜, 他讓你可以問他是非題問題, 不過每問一次就要請一杯飲料, 那你至少要請他幾杯飲料才能確保會得到正解呢?
答案是2杯飲料,這兩個問題可以是:是小明或小楨嗎?、是小華或小琪嗎?當然以上的問題可以任意更改名字,不過結果都是等價的。
計算方法其實不難,思考邏輯就是,一個是非答案可以把可能性減一半,所以只要知道所有可能的數量(上例中為4)是2的幾次方即可,用數學式計算就是:
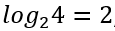
然而這個計算方式是假設每個人得第一名的機率都一樣,如果你先前就知道某一人最常得第一名,那你就有機會用更少的飲料得到答案,因此應該把機率也考量進公式中,修正後的式子為:
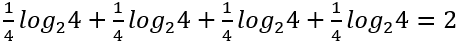
所以如果小明比其他人多一倍的機率得第一,答案就會是:
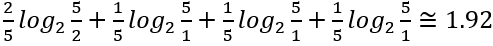
算出了比較低的熵,由此我們得知,越隨機而無法掌握(混亂)的事件,其資訊熵越大,這個觀點與熱力學中的熵,可以說是如出一轍。
最後,我們將資訊熵的標準式子列出:
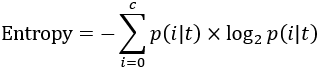
人工智慧與熵的關係
那麼現在當紅的人工智慧AI,又與熵有什麼關係呢?事實上,關係還不小呢!人工智慧的發展從機器學習到深度學習,都可以見到熵的影子,以下我們就來看看熵在人工智慧中扮演的角色。
決策樹的熵
在深度學習還沒發展起來之前,最常見的演算法之一就是"決策樹",它的原理是利用數個是非問題將資料進行分類,進而得到結果,例如,我們想知道一杯咖啡好不好喝,那麼機器便會生成以下決策樹,告訴我們答案:

而決策樹生成的方法,便是羅列出所有是非題,並找出能將資訊熵降到最低的那個問題作為下一個分支,最後就成了有數個分支的樹狀結構了。
神經網路的熵
深度學習是基於神經網路這個結構發展的,它的概念也不難懂,就是將資料輸入進神經網路中,得到一個預測值後,在與真實答案進行比對並計算誤差,然後用這個誤差去修正網路中大量的參數。計算誤差是此演算法中相當重要的部分,我們稱之為損失函數。
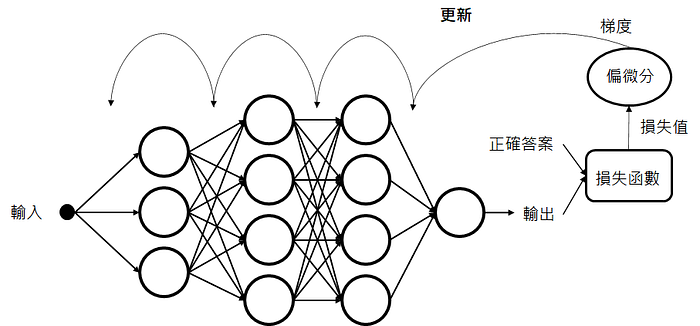
這個損失函數會根據不同問題,而有不同的設計,重點是它一定要符合:越接近真實答案,損失值越小的原則。目前要處理分類問題,最常使用的損失函數便是"交叉熵(cross entropy)",其式子為:
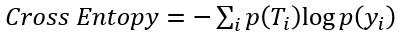
它與先前的資訊熵式子相當類似,其中T代表真實答案,而y代表預測結果,上式中在計算的即是:
兩資料之間的分布差異。
或是你也可以想成:兩資料相比的混亂程度。總之,我們可以知道,他們之間如果差異越小,得到的交叉熵也會越小,這就完全符合了損失函數的原則,因此拿來做為分類問題的損失函數可說是再適合不過了。
總結:熵減可能無法倒轉時間,但能創造生命
目前為止,我們都還沒有發現違背熱力學第二定律的現象,不過若不考量封閉系統的話,熵減是很常見的,尤其在地球上。
諾貝爾獎得主物理學家薛丁格,便在其著作《生命是什麼》一書中提到:
生命是靠著攝取負熵來減少或保持它的熵。
美國宇航局,尋找火星生命科學家之一的詹姆斯·拉夫洛克(James Lovelock)也說:
我想尋找一個熵減少的徵兆,因為這是生命必須有的一般跡象。
再看看神經網路的訓練過程,也是不斷的將熵減少。或許我們無法利用熵減來製造時間機器,但可能在未來做出相當接近人類的人工智慧,甚至擁有了生命也說不定呢!
熵的介紹就到這邊啦,想看更多相關知識的朋友,可以關注我們、想更深入理解深度學習、神經網路的朋友,不妨參考以下的推薦書和學習套件喔:
Deep learning 深度學習必讀 — Keras 大神帶你用 Python 實作
Flag’s 創客‧自造者工作坊 用 Python 學 AIoT 智慧聯網

